We’ve all been there: a PDF drops into your inbox and you need to tweak it quickly before sending it on somewhere - but you don’t have access to the original document. Enter WinZip PDF Pro’s PDF editor, giving you the ability to add text, edit existing text, and crop pages any way you like directly in the PDF.
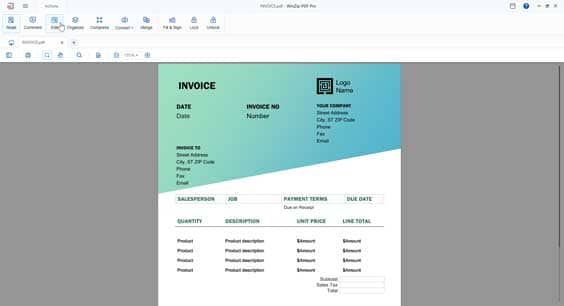
Use WinZip PDF Pro to add text directly to a PDF. Tweak existing text or add completely new paragraphs in the same style as the original content. All you need to add text to PDFs is WinZip’s PDF editor and the PDF you want to add text to.
Filling out a form is one of the most common situations you’ll need to add text to a PDF, and it can be frustratingly difficult. That’s why we added the Edit PDF feature to WinZip PDF Pro, so all you need to do is open up the PDF and add your text to the form to complete it.
Have you noticed an error in one of the pages of the PDF? Or does a document include sensitive information like names and contact details that need to be removed before sending it on? Use WinZip PDF Pro to edit the PDF and redact sections of text or even remove entire pages.
Not sure? No problem. Download WinZip PDF Pro for free today and use it without restrictions for seven days. No personal details or credit card details required - simply download it and start using it.
WinZip PDF Pro works completely offline, so nothing is stored on the cloud. It’s a completely digitally secure platform that you can download and use in seconds without needing to worry about who has access to your sensitive documents.
With just 3 simple steps, WinZip PDF Pro makes it super easy to edit a PDF:
Drag and drop your PDF into WinZip PDF Pro.
Select Edit and get to work making your changes. Add and edit text, images, formatting - whatever you like.
Click Apply and save your new PDF to your desired location.
It really is as simple as that to edit a PDF in just a few clicks.
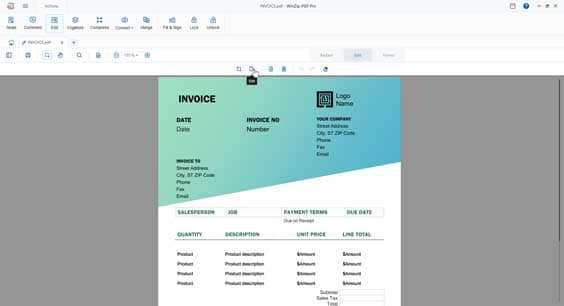
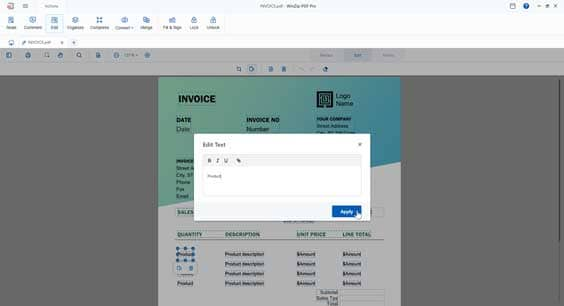
To edit existing text within a PDF, simply bring it into WinZip PDF Pro. Click on the Edit icon and choose the text you want to tweak. The freedom is then yours to remove words, correct typos, and even add entirely new sentences to your PDF.
To freely write new content in a PDF, open up the PDF, select Comment, and the Free Text icon. Then simply click on where you want to add the text and begin typing. When you’re done, save the changes as a new PDF in your preferred location.
The beauty of WinZip PDF Pro is that it is not a cloud-based platform. Once you have installed it onto your computer it works entirely offline. Whether you’re commuting to work through a tunnel or in an office with patchy WiFi, you can edit PDFs in seconds without an internet connection required.
WinZip PDF Pro doesn’t stop at editing PDF files. You can also convert documents such as Word, Excel, Powerpoint and Image files to and from PDFs. Use the tool to also compress PDFs to reduce the size, merge multiple files into one document, lock and unlock them to create password protected files, and annotate them with additional comments. All of this in addition to an easy and seamless way of viewing PDFs.
If you want to use a PDF editor for free, start by installing WinZip PDF Pro. You’ll get access to all of its features without limitations, for free, for seven days. If after the trial you don’t like it, you can continue to use the PDF Reader for free forever. It’s as simple as that, without any personal details required.
Security is a top priority for WinZip PDF Pro, and because it is an offline program there is nothing to worry about when it comes to data breaches. We don’t store or view any documents online - it all happens on your local system. So as long as your computer is secure, your documents are secure.